- 耐久性と可用性が非常に高くデータの中長期保存に最適なストレージ
- コンテンツ配信用の画像データなどをS3に保存して、CloudFrontを利用して配信する

- S3はバケット単位で保存スペースを区分し、オブジェクト単位でデータを格納する

S3ストレージの特徴
- ブロックストレージ
└EC2にアタッチして活用するディスクサービス
└ブロック形式でデータを保存
└高速/広帯域幅
└EBS/インスタンスストア - オブジェクトストレージ
└安価かつ高い耐久性をもつオンラインストレージ
└オブジェクト形成でデータを保存
└デフォルトで複数AZに冗長化されている
└S3/Glacier - ファイルストレージ
└複数のEC2インスタンスから同時にアタッチ可能な共有ストレージサービス
└ファイル形成でデータを保存
└EFS
バケット
ユーザーが利用する1つのストレージ単位をバケットとして作成する
- S3を利用する際に1つのバケットを作成して、そこにオブジェクト(ファイル)を格納する
- バケットはリージョンに設定する
└AZやVPCの範囲外 - バケットにはグローバルに一意の名前を設定することが必要
つまり、全世界のAWSユーザーで異なる名前を設定する - 命名規則を守る必要がある
オブジェクト
バケットに保存されるデータの単位をオブジェクトと呼ぶ。
オブジェクトは以下の要素で構成されている。
- key
└オブジェクトの名前であり、バケット内のオブジェクトを一意に識別 - value
└データそのものであり、バイト値で構成される - バージョンID
└バージョン管理に用いるID - メタデータ
└オブジェクトに付随する属性の情報 - サブリソース
└バケット構成情報を保存および管理するためのサポートを提供
例)アクセスコントロールリスト(ACL)
プレイフィックス
オブジェクトキー名の先頭にある文字列。
オブジェクトはプレイフィックスを利用して整理しり保存する。
例)バケット(udemy-test)にsampleというjpgファイルを整理した例
└udemy-test/photos/2006/January/sample.jpg
└udemy-test/photos/2006/February/sample2.jpg
└udemy-test/photos/2006/February/sample3.jpg
└udemy-test/photos/2006/February/sample4.jpg
オブジェクトキー
オブジェクトキーはプレイフィックス+オブジェクト名(ファイル名)で構成される。
例)バケット(udemy-test)に以下の2つのオブジェクトキーを持つオブジェクトがある場合
└udemy-test/Development/Projects.xls
Developmentというプリフィックス+オブジェクト名(ファイル名)→キー
└udemy-test/s3-dg.pdf
オブジェクト名(ファイル名)→キー
オブジェクトURL
オブジェクトにアクセスする際はオブジェクトURLという固有のURLからインターネット経由でアクセスできる

S3のデータ容量制限
S3のストレージ容量は無制限であり、0KBから5TBまでのデータを保存可能
- バケット
└オブジェクトの保存場所
└リージョンに設置されるため、名前はグローバルでユニークにする。
└データ保存容量は無制限であり、自動でストレージ容量が拡張される。 - オブジェクト
└S3に格納されるファイル形式で、オブジェクトに対してURLが付与される。
└バケット内に保存可能なオブジェクト数は無制限 - 保存可能なオブジェクトサイズの制限
└オブジェクトあたりのデータサイズは0KBから5TBまで保存可能
バージョン管理
ユーザーによる誤操作でデータ削除などが発生してもバージョンから復元できる
- バケット単位でオブジェクトのバージョンを管理する
- バージョンごとにオブジェクトが保管さあれる
- ライフサイクルルールによってバージョンが保存される期間を設定できる
- バージョンニングが有効になる前のバージョンはnullとなる
【現在】 【過去分】
バージョンID_00011 バージョンID_00010
①データA ①データA
②データB ②データB
③データC ③データC
バージョンID_00012
①データA
②データB
③データC
ストレージクラス
| タイプ | 特徴 | 性能 | 追加料金 |
| STANDARD | ◎複数個所にデータを複製するため耐久性が非常に高く、頻繁に利用するデータを大量に保存するのに向いている ◎データは3AZ以上で分散保存される |
■耐久性 99.999999999% ■可用性 99.99% |
■最低利用料金 なし ■データ取得料 なし |
| STANDARD-IA | ◎IAはInfrequency Accessの略であり、低頻度アクセスデータ用のストレージ ◎Standardに比べて安価だが、One Zone-IAよりは高い |
■耐久性 99.999999999% ■可用性 99.9% |
■最低利用料金 30日 ■データ取得料 GB当たり取得料 |
| One Zone-IA | ◎低頻度アクセス用のストレージだが、マルチAZ分散されていないため可用性が低く、重要ではないデータ向け。その分Standard IAよりも値段が安い | ■耐久性 99.999999999% ■可用性 99.5% = AZ |
■最低利用料金 30日分 ■データ取得料 GB当たり取得料 |
| S3 Intelligent Tiering | ◎高頻度と低頻度という2つのアクセス階層を利用し、アクセスがあるファイルは高頻度(標準クラス)に維持しつつ、アクセスがないファイルは低頻度(標準IAクラス)に自動で移動する ◎アクセスパターンがわからない場合に利用 |
■耐久性 99.999999999% ■可用性 99.9% |
■最低利用料金 30日 ■データ取得料 なし |
| S3 Glacier Flexible Retrieval (通常のGlacier) |
◎1年に1〜2回アクセスされ、非同期で取り出されるアーカイブデータ向け ◎通常のデータ検索で(3〜5時間)を要する ◎迅速取り出しで(2〜5分)で取り出し可能 ◎一括検索で(5〜12時間)で無料 ◎ライフサイクルマネジメントで指定 ◎ボールトロック機能でデータを保持 |
■耐久性 99.999999999% ■可用性 99.99% |
■最低利用料金 90日 ■データ取得料 GB当たり取得料 |
| S3 Glacier Instant Retrieval | ◎アクセスされることがほとんどなく、ミリ秒単位の取り出しが必要な長期間有効なデータ向け ◎医用画像やニュースメディアなど ◎S3 Standardと同じパフォーマンスのミリ秒単位でのデータの取り出し |
■耐久性 99.999999999% ■可用性 99.9% |
■最低利用料金 90日 ■データ取得料 GB当たり取得料 |
| Amazon Glacier Deep Archive | ◎最安のアーカイブ用ストレージ ◎7〜10年以上保持される長期間使用されるものの、めったにアクセスされないデータ向け ◎標準の取り出し速度で12時間以内にデータを取得 ◎大量取り出しで48時間以内にデータを取得 ◎ライフサイクル管理で指定 |
■耐久性 99.999999999% ■可用性 99.99% |
■最低利用料金 180日 ■データ取得料 GB当たり取得料 |
S3の利用コスト
ストレージのコストを比較するとインタンスストアを除けば、最も値段が安いのはGlacier deep archive
| S3のデータ容量に応じたコスト | ◎標準:1GB当たり 0.025USD/月 ◎S3 Intelligent Tiering:標準と標準IAの組合せ ◎標準IA:1GB当たり 0.019USD/月 ◎One Zone IA:1GB当たり 0.0152USD/月 ◎Glacier:1GB当たり 0.005USD/月 ◎Glacier deep archive:1GB当たり0.002USD/月 |
| EBSの汎用ストレージコスト | ◎汎用:1GB当たり 0.12USD/月 ◎コールドHDD:1GB当たり 0.03USD/月 |
| EFSストレージコスト | ◎標準:1GB当たり 0.36USD/月 ◎低頻度アクセス:0.0272USD/月 |
| インスタンスストア | EC2インスタンスに含まれる |
| リージョン | リージョンごとに価格が異なる |
| データ容量 | ◎データ容量:データ容量と保存期間に応じて料金がかかる (GB当たり) ◎S3 Intelligent Tiering、IAストレージには、最低30日間の料金 |
| リクエストとデータ取得 | ◎データに対するリクエストに応じて料金がかかる (1000リクエスト当たり) ◎データを取得した量に応じて料金がかかる (GB当たり) |
| データ転送 | ◎データ転送イン:無料 ◎インターネットへのデータ転送アウト(GB当たり) ◎S3からAWS内でのデータ転送アウト(GB当たり) |
リクエスト払い
S3バケットはデータ取得の際にも料金が発生する場合があるため、リクエスト払いはデータ取得したアカウントに課金する
| データ保存コスト | データ通信コスト | |
| リクエスト払い無効 | バケットの所有者がデータの保存コストを支払う | バケットの所有者がデータのダウンロードコスト(通信料)を支払う |
| リクエスト払い有効 | バケットの所有者がデータの保存コストを支払う | データダウンロードをリクエストしたアカウントがデータのダウンロードコスト(通信料)を支払う |
アクセス管理
アクセス管理にはユーザーベースのIAMとリソースベースのバケットポリシーとACLを主に利用する
| 管理方式 | 特徴 |
| IAMユーザーポリシー | ◎IAMユーザーに対してAWSリソースとしてのS3へのアクセス権限を設定 ◎内部のIAMユーザーやAWSリソースへの権限管理 |
| バケットポリシー | ◎バケットのアクセス権をJSONで設定する 1つのバケットに対して1つだけ設定可能 ◎外部ユーザーやアプリケーションなども管理可能 |
| ACL | ◎バケット/オブジェクト単位でのアクセス権限をXMLで設定することができる ◎オブジェクトに個別に設定可能 |
| アクセエスポイント | ◎S3バケットにアクセスポリシーを設定する ◎バケットのアクセス権をJSONで設定する 1つのバケットに対して複数設定可能 ◎外部ユーザーやアプリケーションなども管理可能 |


アクセスポイント
アクセス先に応じてアクセスポイントを作成して、ポリシーを適用してアクセス設定が可能になる

ブロックパブリックアクセス
インターネットからのアクセスをブロックする機能で、バケット作成時に初期設定で有効化されている

事前署名付きURL
事前署名付きURLにより、特定のユーザーのみがアクセスできる特別なURLが利用可能になる

S3の通信暗号化
S3の公開エンドポイントはデフォルトでHTTPSが利用されており、HTTPSによる自動的にSSL/TLS通信が実施される
- HTTPエンドポイント
└非暗号化されたURLを利用したアクセス
└選択可能だが、デフォルトでは設定されておらず、非推奨となっている。 - HTTPSエンドポイント
└暗号化された通信経路でSSL/TLS通信が自動で適用される
└ユーザー側で証明書などの設定は必要ない
S3の保管データの暗号化
S3へのデータ保管時に暗号化形式として以下の4つの形式から選択する
| 暗号化方式 | 特徴 |
| SSE-S3 | ◎S3の標準暗号化方式で簡易に利用可能 ◎暗号化用のマネージドキーの作成/管理をS3側で自動で実施 ◎ブロック暗号の1つである256ビットのAdvanced Encryption Standard(AES-256)を使用してデータを暗号化 |
| SSE-KMS | ◎AWS KMSに設定したキーを利用した暗号化を実施 ◎ユーザー側でAWS KMSを利用して暗号化用のマネージドキーを作成/管理することが可能 ◎AES-256を利用 |
| SSE-C | ◎ユーザーが指定した暗号化用のマネージドキーをデータと共に送付して、サーバー暗号化(SSE-C)を実施する ◎利用設定や管理が複雑になるのがデメリット |
| クライアントサイト暗号化(CSE) | ◎クライアント側の暗号化では、Amazon S3に送信する前にデータを暗号化する方式 ◎アプリケーションに保存したマスターキーを使用 |
- SSE-S3

- SSE-KMS

- SSE-C


- CSE

S3 MFA Delete
バージョニング機能のオプションとして、オブジェクト削除時にMFA認証を必須にできる
※バージョニングを有効化した時のみ利用可能
※バージョニングファイルを削除する際にMFAが必要となる
※バージョニングを停止する際にMFAが必要となる
※バケットの所有者のみがMFA Deleteを設定可能

オブジェクトロック
アップロードされたデータを更新と削除をできないようにする機能
データが更新されないことを保証する
- リテンションモード
└ガバナンスモード:特別なアクセス許可なしに、ユーザーはオブジェクトのバージョンの上書きや削除、ロック設定を変更することはできない。
└コンプライアンスモード:ルールユーザーを含め、ユーザーは保護されたオブジェクトのバージョンを上書きまたは削除することはできない。リテンションモードを変更することはできず、保持期間を短縮することはできない。
保持期間中にオブジェクトのバージョンを上書きまたは削除はできない。 - オブジェクトロックの有効期間
└期間指定:一定期間の間オブジェクトが削除されないようにする。
└リーガルホールド:永続的にオブジェクトが削除されないようにする。
リーガルホールドには関連する保持期間はなく、削除するまで有効とする。
S3イベント
S3オブジェクト操作と連動したシステム連携処理を実現
└バケット内イベンどの発生をトリガーにして、SNS/SQS/Lamdaに通知設定が可能
└S3オブジェクト操作と連動したシームレスなシステム連携処理を実現

S3のパフォーマンス
S3はプレフィックスに応じてリクエスト処理が可能なパフォーマンスが調整できる
└プレフィックスごとに1秒あたり3,500回以上のPUT/COPY/POST/DELETEリクエストまたは5,500回以上のGET/HEADリクエストが可能
└発生するリクエスト率が高い場合(オブジェクトに対して1秒あたり5,000リクエストを超える率が持続される)にHTTP503slowdownレスポンスが発生する
└データ転送時に約100〜200ミリ秒の一定のレイテンシーを実現できる
S3パフォーマンスの向上
カスタムプレフィックスを利用して並列処理をすることでパフォーマンスを向上させる
└パフォーマンスを最適化するためにカスタムプレフィックスを設定する
例えば、日付ベースの順次命名を使用する
└カスタムプレフィックスを作成してデータ処理の並列化が可能となる
例えば、10個のプレフィクスで読み取りを並列化すると、1秒あたり55,000回の読み取りが可能となる
└複数の接続でデータを同時にGETまたはPUTするアプリケーションを使用することで高スループット転送が可能となる
S3の整合性モデル
S3はデータ登録/更新/削除などの処理時に強い整合性モデルを採用している
| データ処理 | 整合性モデル |
| 新規登録 | ◎Consistency Read ◎登録後即時にデータが反映される |
| 更新 | 202年12月より強い整合性モデルに変更されたため、齟齬は発生しない |
| 削除 | 202年12月より強い整合性モデルに変更されたため、齟齬は発生しない |
アップロード時の整合性確認
Content-MD5ヘッダーを使用してアップロードされたオブジェクトの整合性を確認することができる
1. オブジェクトのbase64でエンコードされたMD5チェックサム値を取得する
2.アップロード中のオブジェクトの整合性を確認する
ただし、アップロードがAWS署名バージョン4で署名されている場合、代わりにx-amz-content-sha256ヘッダーを使用する必要がある
マルチパートアップロード
大容量オブジェクトをいくつかに分けてアップロードする機能
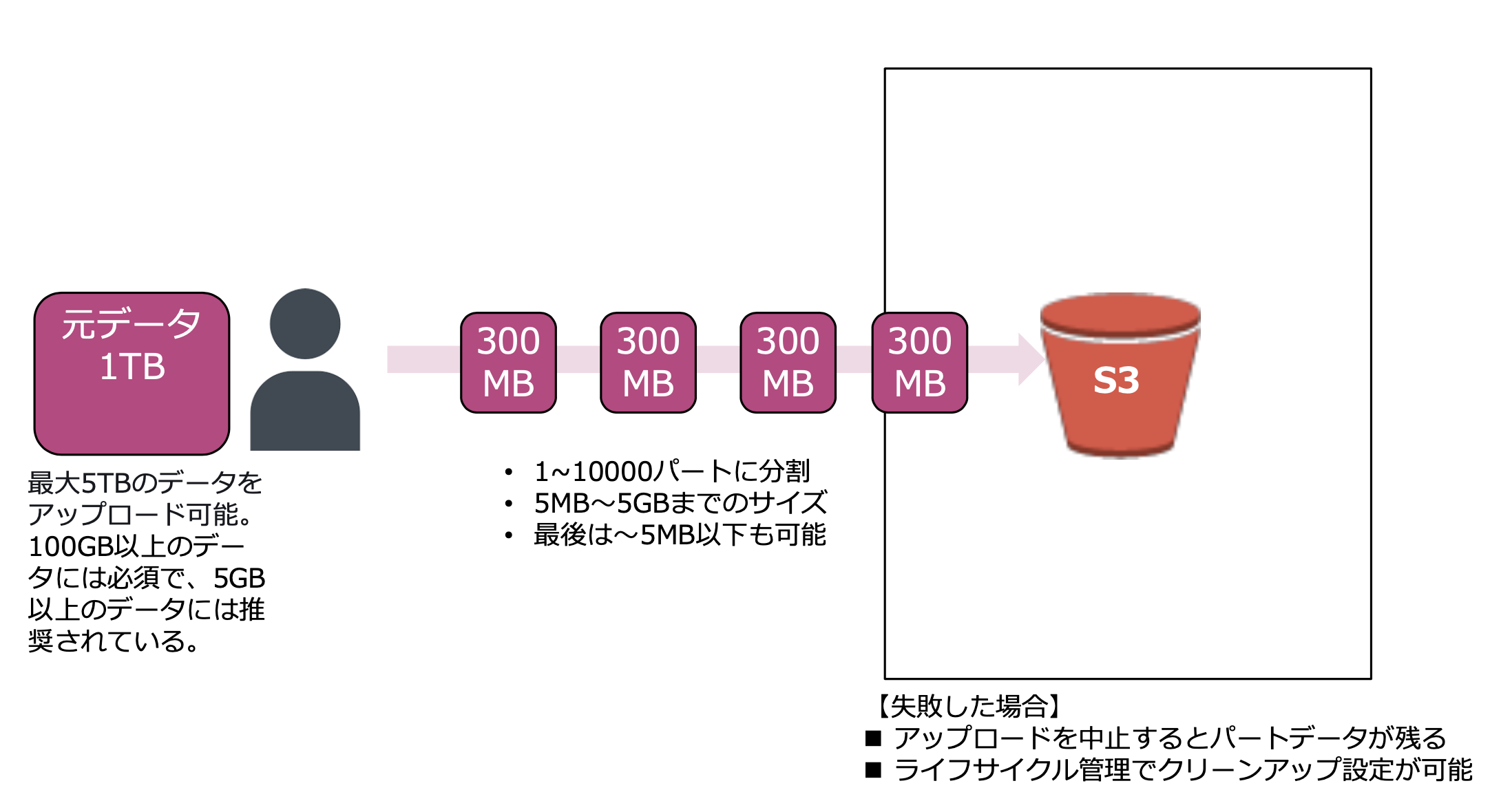
S3 Transfer Acceleration
データ転送元から地理的に一番近いエッジロケーションを利用して高速にデータアップロードを実施する

静的Webホスティング
S3を利用して簡易な静的Webサイトを作ることができる機能
リージョンに応じてAmazon S3ウェブサイトエンドポイントは以下の2つの形式のいづれかになる
└S3-WebSite-ダッシュ(-) リージョン- http://bucket-name.s3-website-Region.amazonaws.com
└S3-WebSite-ドット(.)リージョン- http://bucket-name.s3-website.Region.amazon.com

- メリット
└サーバーなしにWebサイトをホスティング可能
└サーバーが必要ないため値段が安い
└マルチAZの冗長化を勝手にしてくれており、運用いらず
└Route53で独自ドメインを設定可能
└CloudFrontによる配信可能 - デメリット
└サーバーサイドスクリプト言語を実行するなどの動的サイト不可
└単独ではSSLが利用できず、SSL設定にはCloudFrontが必要 - 構築手順
ブロックパブリックアクセスを無効化する
↓
バケットポリシーでバケットの読取許可を設定する
↓
Index.htmlなどのインデックスドキュメントをバケット内に保存する
↓
静的Webホスティングの設定画面でIndex.htmlなどのインデックスドキュメントを設定し、有効化する - Route53によるドメイン設定
└トラフィック先としてS3Webサイトエンドポイントへのエイリアス[Region(地域)]を選択する
└レコードタイプとしてエイリアスレコードのAレコード(IPv4)タイプを利用してドメインを設定する
└ターゲットの正常性の評価にはデフォルト値を設定する
└バケット名とドメイン名またはサブドメイン名と同じにすることが必要
ライフサイクル管理
時間に応じてオブジェクトのストレージクラスの変更や削除を自動的に行うルールを設定できる
- 設定方法
└バケット全体やプレフィックスに設定
└オブジェクト更新日を基準にして日単位で指定し、毎日0:00UTCにキューを実行
└最大1000までのライフサイクルルールを利用可能
└IAに移動できるのは128KB以上のオブジェクト
└MFA Deleteが有効だと設定不可


S3のレプリケーション
S3バケットはレプリケーションによって別のバケットにデータを複製することができる
- 同一リージョンレプリケーション(SRR)
└同一リージョンのバケットに同じデータを保存する
└本番用のデータとテスト用のデータと分ける際などにレプリケーションしてバケットを複数設定 - 別リージョンのレプリケーション(CRR)
└別リージョンのバケットに同じデータを保存する
└災害対応としてデータを別リージョンに保存
└リージョン別のアクセスを低レイテンシーにする
クロスリージョンレプリケーション
S3はリージョン間を跨ぐクロスリージョンレプリケーションにより耐障害性を高める
- レプリケーションのトリガー
└レプリケーションを有効後に、バケットにおけるオブジェクトの作成/更新/削除をトリガーにレプリケーションを実行する
└有効前のデータはレプリケーションされない - 設定
└事前にバージョニング機能を有効にする必要がある
└レプリケーション先となるバケットは別リージョンに設置
└双方向レプリケーションも可能
└データ転送費用が発生
└レプリケーションは3つ目のバケットには連鎖しない
S3のクロスアカウントアクセス
別のアカウントのIAMユーザーやロールからのアクセスを許可する設定

| 設定方式 | 詳細 |
| バケットポリシーとIAMポリシーによる許可 | ◎S3バケットへのアクセスを許可するIAMポリシーを設定する ◎IAMユーザーとロールにIAMポリシーを設定する ◎S3バケットへのクロスアカウントアクセスを許可する場合は、バケットポリシーでアカウントを指定して許可を行う |
| ACLとIAMポリシーによる許可 | ◎S3バケットへのアクセスを許可するIAMポリシーを設定する ◎IAMユーザーとロールにIAMポリシーを設定する ◎S3バケットの特定オブジェクトへのクロスアカウントアクセスを許可する場合は、ACLでアカウントを指定して許可を設定 |
| IAMロールによる許可 | ◎IAMロールの権限移譲を利用して、S3バケット/オブジェクトへのプログラムによるアクセスまたはコンソールアクセス用のクロスアカウントのIAMロールを設定する ◎AssumRoleの実行を許可したロールにより別アカウントのユーザーに権限を移譲する |
クロスオリジンリソースシェアリング(CORS)
1つのS3を利用したWebアプリケーションのドメインから、別のドメインが利用するS3リソースを相互利用する機能

例えば、2つの静的WebホスティングされたS3バケットリソースを1つのWebサイトとしてオリジンサーバーで表示される

正しいCORSヘーダーを利用しない他のオリジンからのリクエストは実行しない

udemy.domが静的WebサイトとしてS3バケットのリソースを利用している

S3バケットの利用状況分析
S3バケットの利用状況を分析することで、効率的な利用方法や安全な利用がされているかを支援する
| 分析機能 | 特徴 |
| S3サーバーアクセスログ | ◎バケットに対するリクエストの詳細が記録される ◎アクセスのログ情報は、セキュリティやアクセスの監査に利用できる |
| S3アクセスアナライザー | S3バケットに対して任意のユーザーや他のAWSアカウント(組織外のAWSアカウントを含む)にアクセスを許可が適切にされているかを評価/警告する |
| S3ストレージクラス分析 | ◎データのアクセス頻度の分析 ◎バケット内の一定期間のストレージアクセスパターンを分析し、標準ストレージに格納されたデータを標準IAストレージクラスに移動すべきかを判断できる |
| Amazon S3 Storage Lens | ◎データの使用状況とアクティビティの分析 ◎バケットの使用状況アクティビティのメトリクスを集計することができる |
サーバーアクセスログ
S3にアクセスした際のログを取得することが可能。
バケットとプレフィックスをターゲットに設定する。

S3アクセスアナライザー
S3のアクセス状況がアクセスポリシーに沿っているか確認し、不正なアクセスの有無を監視する
- IAMアクセスアナライザーと連動したS3向けの機能
- バケットポリシー/ACLに沿ってポリシー違反がないかをモニタリング
- パブリックバケットまたは共有バケットアクセスを解析して、その解析結果を表示する
- バケットアクセスのソースを検証する場合は、列の情報を使用して、迅速で正確な是正処置を実行する
ストレージクラス分析
S3バケットの利用状況を確認して最適な利用設定を支援する
- バケット内のデータのアクセスパターンを確認することができる
- レポートは日次でCSV形式で出力される
- 最初のレポートの抽出には24時間〜48時間を要する
- アクセス頻度の低いデータや保存期間を確認して、ライフサイクルルール設定に活かすことができる
- 主に標準ストレージから標準IAに移行するべきオブジェクトを確認することが可能となる
S3 Storage Lens
バケットの使用状況とアクティビティのメトリクスを集計することができる
- バケットの使用状況とアクティビティのメトリクスを集計することができる
- 組織全体でストレージがどれぐらい利用できるのか、最も急成長しているバケットとプレフィックスが何であるか、などのインサイトを抽出できる
- Amazon S3 コンソールバケットページのダッシュボードではインサイトと傾向を可視化できる
- CSVまたはParquet形式でレポートをダウンロードできる
- ストレージコストの最適化や、データ保護のベストプラクティスに関するレコメンデーション事項が提示される
S3のデータ分析
S3内のデータ検索/解析には用途に応じて複数サービスから選択が可能
- S3 Select(Glacier Select)
└S3の内部機能として有している検索機能で、S3内で直接にクエリを実行し、データをフィルタリングして取得できる
└GZIP圧縮データやCSVやJSONに対して実行可能

- Amazon Athena
└Amazon S3内のデータ直接、簡単に分析できるようにするインタラクティブなクエリサービス
└Athena SQL クエリでSageMaker機械学習モデルを呼び出し、 機械学習による推論も実行可能
└S3バケット内のデータを指定し、スキームを定義し、標準的なSQLを使用してクエリの実行することができる
└実行したクエリに対してのみ料金が発生する
└AWS Glueデータカタログと連携して、さまざまなサービスにわたるメタデータの総合リポジトリを作成できる
└データソースのクロールとスキーマの解析、新規および修正したテーブル定義とパーティション定義のカタログへの入力、スキーマのバージョニング保持が可能

- Amazon Macie
└機械学習によりAmazonS3の秘密データを検出、分類、保護する、フルマネージド型サービス
└秘密データ検出や調査を実施する
└大規模なデータセット内にある機密データの検出を自動化し、データ保護のコストを削除する
└AWSアカウントと共有されているバケットのリストを含む、Amazon S3バケットのインベントリが自動的に提供される
└S3バケットに機械学習とパターンマッチング手法を適用して、個人識別情報(PII)などの機密データを特定してアラートを発信する - Amazon Redshift Spectrum
└Amazon S3の格納データに対して、Amazon Redshiftから直接クエリを実行できる機能
└Redshiftクラスターが起動されている前提であるため、Redshiftを利用している場合にお勧め

Amazon S3 Glacier
- Amazon S3 Glacierでは、データは「アーカイブ」に保存される
- 1つのアーカイブの最大サイズは40TB
- 保存可能なアーカイブ数とデータ量に制限ないし
- 各アーカイブには作成時に一意のアーカイブIDが割り当てられ、作成後はアーカイブを更新できない
- アーカイブを保存するためのコンテナとして「ボールト」を使用
(1つのAWSアカウントでは、最大1,000個のボールトを使用) - Amazon S3のライフサイクルルールと連携させることにより、Amazon S3データのアーカイブを自動化し、
全体的なストレージコストを削減 - Advanced Encryption Standard(AES)256ビット鍵を使用してデフォルトで自動的に暗号化
- S3と違って直接データをアップロード/取得という処理ができないため、S3ライフサイクル管理からか、プログラム処理によるアップロード/ダウンロードが必要
- Glacierの最低保持期間は90日
Glacierの仕組み
アーカイブに一時的にデータをアーカイブ処理して、ボールトに長期保存するという仕組み
| 管理方式 | 特徴 |
| ボールト | ◎ボールトはアーカイブを格納するコンテナ ◎ボールトはリージョンに作成 |
| アーカイブ | ◎アーカイブは、写真、動画、ドキュメントなどの任意のデータで、S3 Glacierでのストレージの基本単位 ◎各アーカイブは一意のアドレスを持つ |
| ジョブ | ◎アーカイブにSELECT クエリを実行したり、アーカイブを取得したり、ボールとのインベントリを取得したりする実行単位 |
| 通知設定 | ◎ジョブの完了には時間がかかるため、ジョブの完了時にSNSと連携した通知設定が可能 |

Glacierのデータ取り出しタイプ
Glacierのデータ取得タイプの設定に応じてデータ取得時間と取得時の料金が変わる
| タイプ | 特徴 |
| 迅速 | 迅速取り出しでは、アーカイブのサブセットが迅速に必要になった場合にデータに素早くアクセスするモード。 通常1〜5分以内で使用可能 |
| プロビジョニングキャパシティ | プロビジョンドキャパシティーは、迅速取り出しの取得容量を必要な時に利用できることを保証する仕組み |
| 標準 | 標準取り出しでは、数時間以内に全てのアーカイブにアクセスできる デフォルト設定。 通常、標準取り出しは3〜5時間で完了 |
| 大容量 | 大容量取り出しは、最も安価な取り出しオプションであり、大量のデータ(ペタバイトのデータを含む)を1日以内に低コストで取得できます。 通常、大容量取り出しは5〜12時間で完了 |
Glacierのアクセス管理
Glacierのアクセス管理は用途に応じて方式を使い分ける
| 管理方式 | 特徴 |
| IAMポリシー | ◎IAMユーザーやリソースに対してS3サービスへのアクセスを権限を設定する ◎一元的にリソースへのアクセス権限を管理 |
| ボールトポリシー | ◎ボールトで直接アクセスポリシーを定義して、組織内のユーザーや社外ユーザーに対してもボールトへのアクセス権を付与 |
| データ取り出しポリシー | ◎データ取り出しに関する制限を定義 ◎「無料利用枠のみ」に制限。または無料利用枠を超える量を取り出したい場合は、「最大取得率」を指定すると、取り出し速度を制限して、取り出しコストの上限を設定 |
| ボールトロックポリシー | ◎ロックによって変更を禁止することにより、コンプライアンス管理を強力に実施することが可能 |
| 署名 | ◎認証保護のために、全リクエストに署名が必要 |
Glacier Deep Archive
Glacierよりも値段が安くデータ保存が可能だが、データ取得はさらに遅くなる中期保存用ストレージタイプ
- 基本的なデータモデル/管理はGlacierと同じ
- 1GBあたりの月額料金0.00099USDから利用可能でAWSの最低価格
- データは3つ以上のAWSアベイラビリティゾーンにまたがって保存され、S3と同様に99.999999999%の耐久性を実現
- 標準取り出しで、データは12時間以内に取り出すことが可能
- 大容量取り出しで、48時間以内にデータを取り出す大容量取り出しをすることで取得コストを低減できる